GPT-2
GPT-2 was one of the first, and most notable GPT models!
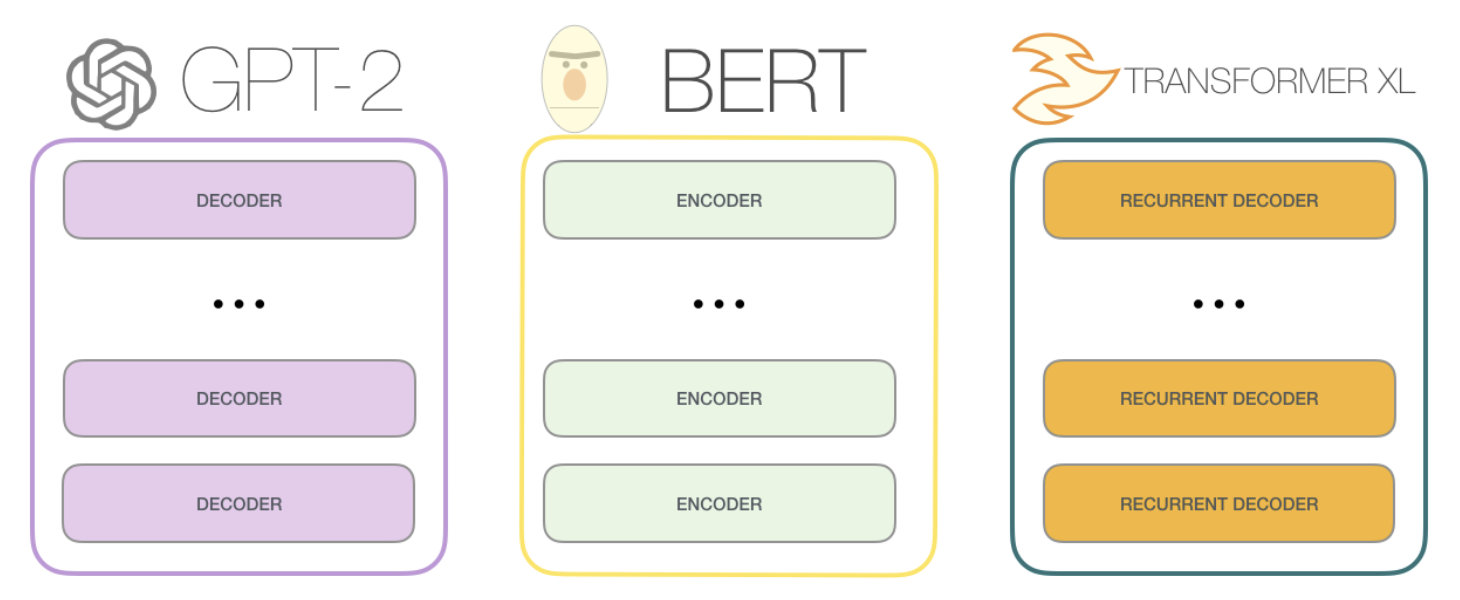
GPT models are Decoder Only, meaning they immediately start to output text in an auto-regressive fashion after receiving input
In Embeddings BERT was discussed to show how we can "attend to" embeddings, and the Self Attention encoder portion was a way to contextualize an entire sentence, before and after a word, but GPT isn't "allowed" to do that
Use Case: Original Encoder-Decoder Transformers were great for machine translation, but that isn't the use case for GPT! GPT is used for things like next word prediction, auto-complete, etc...
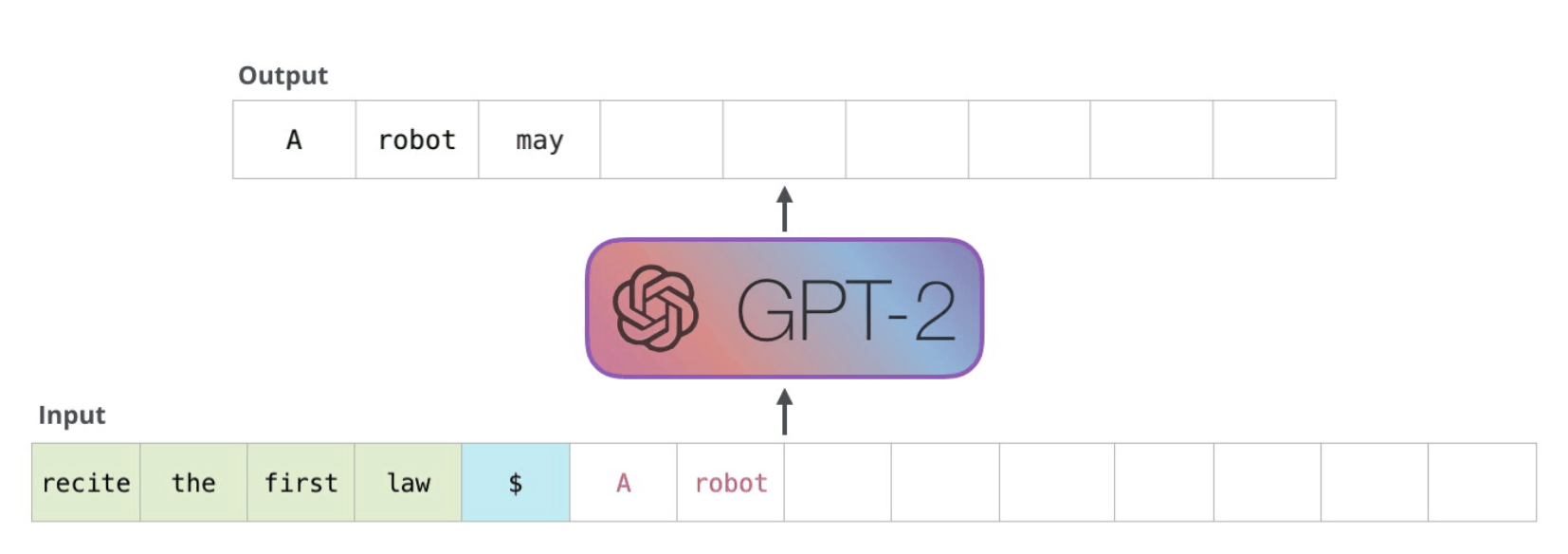
The first good comparison I can think of is to a really good auto-complete where you could have 3-4 words in a message already typed out, and those words would be the queries and keys in Self Attention to help us generate the next words in our SoftMax output layer
History
GPT-2 was trained on a 40GB dataset known as WebText by OpenAI
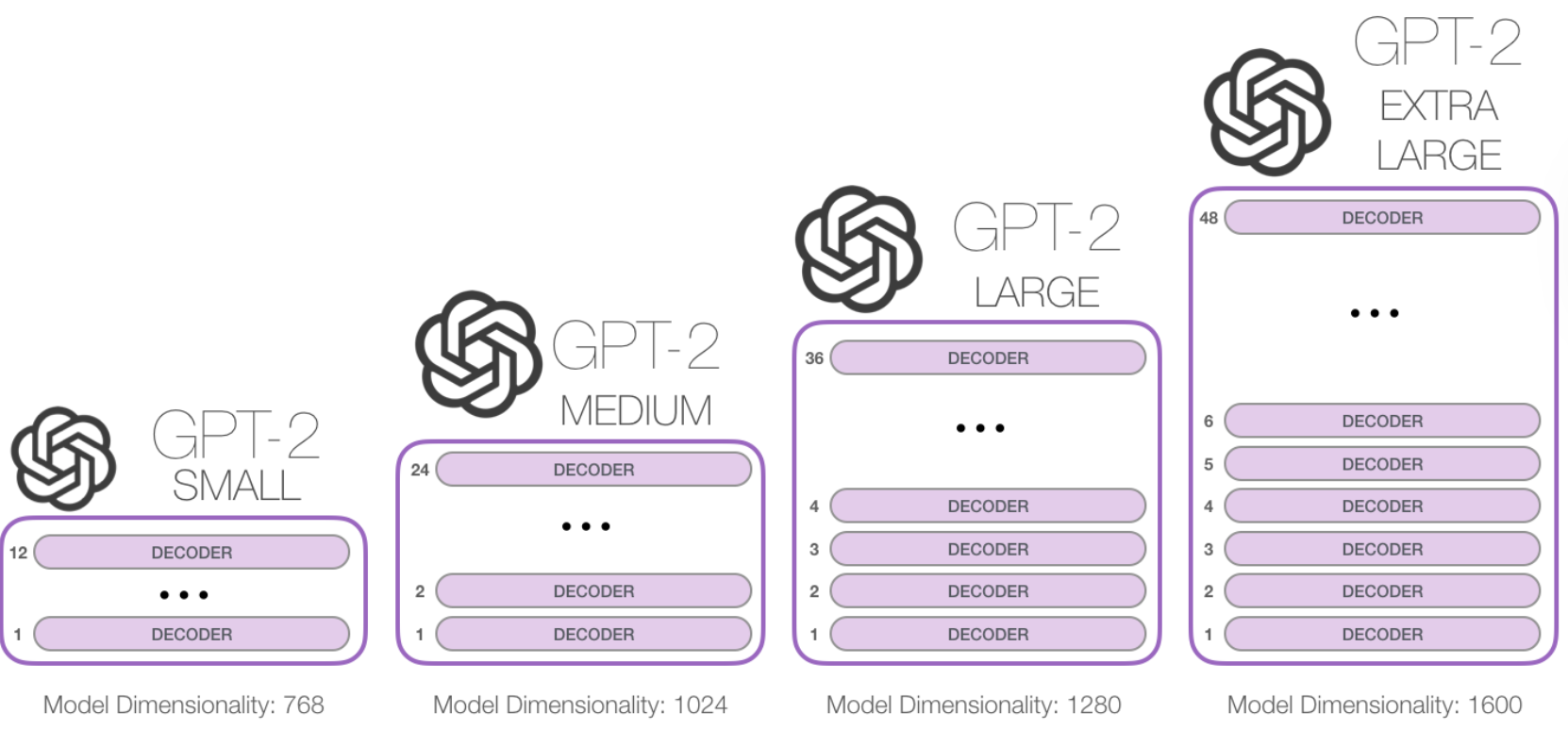
The smallest GPT-2 variant took up ~500MB of storage, and the largest one was ~6.5GB, showing the difference in overall parameter sizes
The number of decoder blocks + context size is one of the distinguishing factors in GPT models as well
Pseudo Architecture
- Input:
- We embed our initial words and use positional encoding as well
- Decoder Only:
- Uses Masked Self Attention
- Auto Regressive:
- The way these models actually work is that after each token is produced, that token is added to the sequence of inputs. And that new sequence becomes the input to the model in its next step.
- This means that we don't encode everything from before and after, we can use the prompt as input and then each generated word is also included in the future generation
- Output:
- Compare our output, attended to, embedding with our vocabulary list to create probability distribution over all words
- Use the
top_kparameter and select words from the resulting sample set for our output generated word
Architecture
Input
Since we still need a numeric representation of our text we need to embed the input
Most of these models will use WordPiece embeddings to expand their dictionary beyond singular words
Tokenize our sentence input into Word Pieces
- Will have some words get split into tokens like
embeddings -> [em, ###bed, ###ding, ###s] - Allows us to still embed words we may not have seen before
We also include Positional Encoding
**The very first word generated will get the special start token <s> along with the prompt
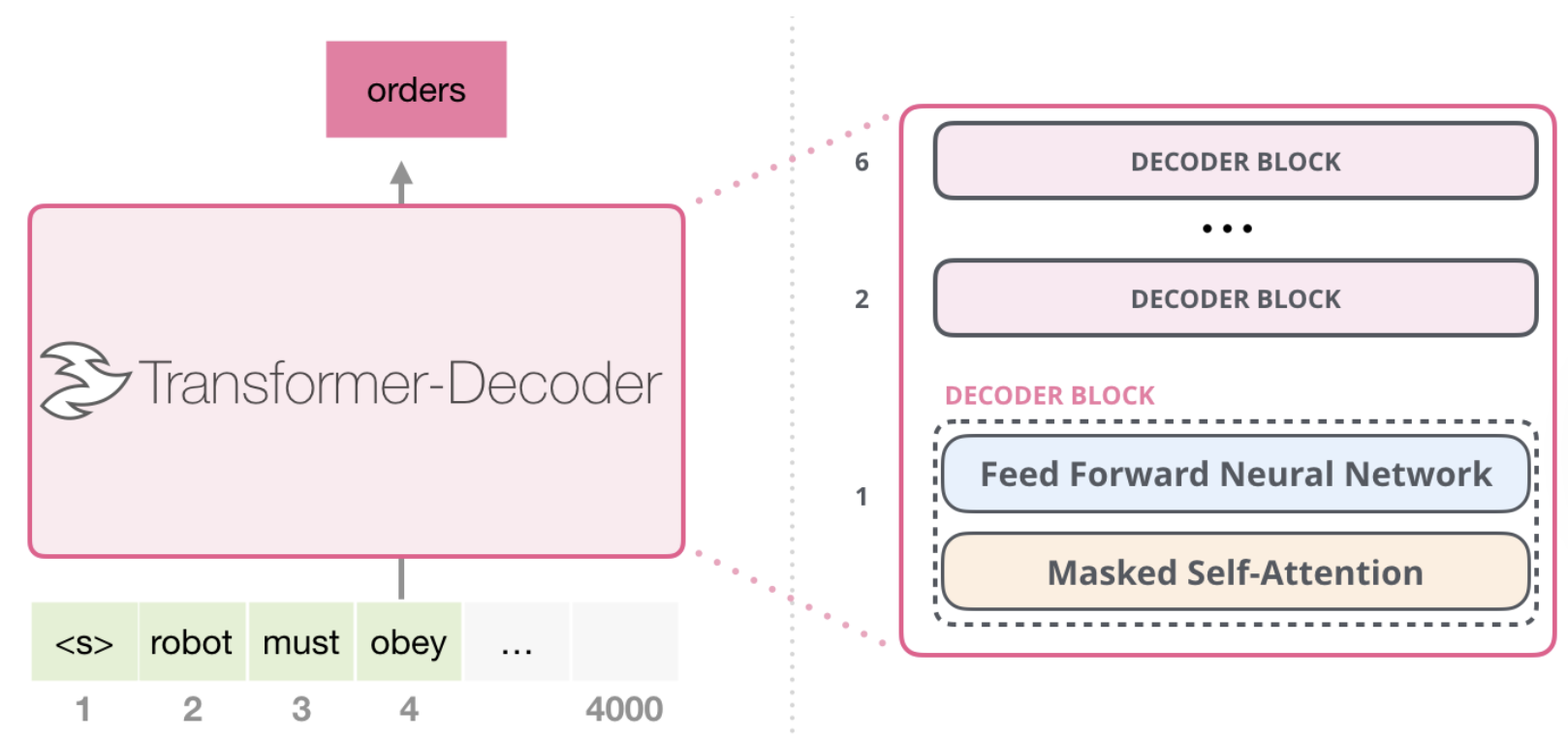
Transformer Decoder Only Block
Unlike the Decoder Block in Encoder-Decoder, the Decoder blocks in Decoder-Only models only have 2 layers:
- Masked Self Attention
- Feed Forward NN
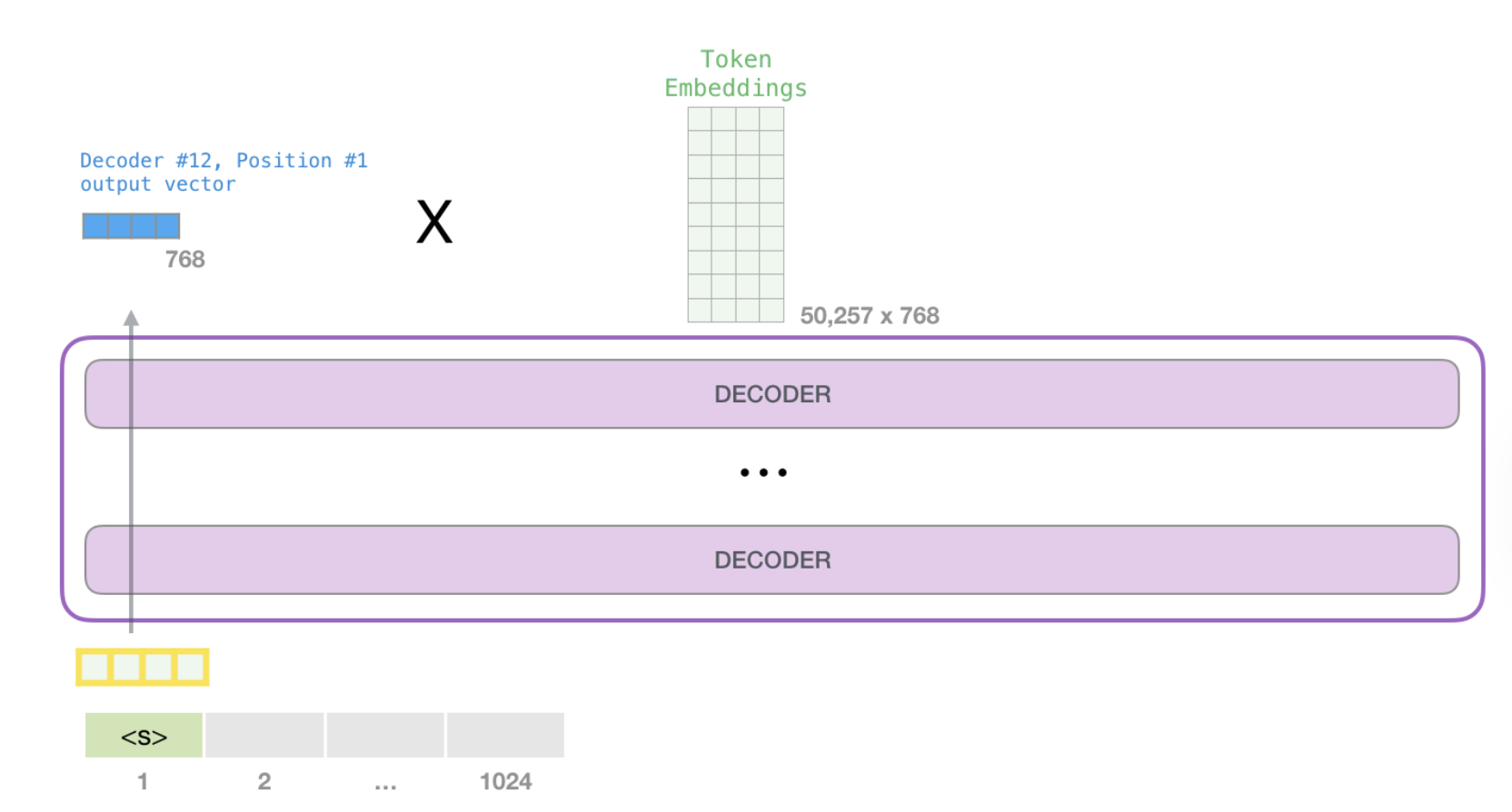
Logits Output
After an embedding has gone through Masked Self Attention, and the Decoder(s) have output an attended to representation of the next word to generate, we must compare that to the known vocabulary we have
In this step we multiple our embedded output vector by our vocabulary, and then get a numeric probability for each potential output word
Output Parameters
- Top-K: Choosing a set of words to sample from for our final output
- If
k=1then we just choose the output word with the highest probability - Typically
kis set to something larger, such ask=40, and then we use the probability of thta word as the sampling distribution- i.e. if there's 1 word with 60% chance and 39 other words with 1% chance, we'll still most likely choose the 60% word, but there's always potential randomness with the other 39!
- If
Completed!
At this point we've completed 1 word! And the model will continue to output words unless it's context window is filled (GPT-2 had 1,024) or it generates an <EOS> End of Sentence Token